 Buy Crypto
Buy Crypto- Markets
 Futures
Futures- Spot
- Copy Trade
- Earn
- More
China's AI Compute Power Counterstrike
Article | Sleepy.txt
Eight years ago, ZTE suffered a sudden cardiac arrest.
On April 16, 2018, a ban from the U.S. Department of Commerce's Bureau of Industry and Security brought ZTE, the world's fourth-largest telecommunications equipment provider with 80,000 employees and annual revenue exceeding a hundred billion, to a standstill overnight. The ban was simple: for the next seven years, it prohibited any U.S. company from selling parts, goods, software, or technology to ZTE.
Without Qualcomm's chips, base stations ceased production. Without Google's Android license, phones were left without a usable system. Twenty-three days later, ZTE announced that its main business operations had become impossible.
However, ZTE ultimately survived, but at a cost of 1.4 billion U.S. dollars.
A $1 billion fine, to be paid in a lump sum; a $400 million escrow deposit, placed in a U.S. bank's custody account. In addition, a complete overhaul of all executives, accepting the presence of a U.S. compliance oversight team. In 2018, ZTE incurred a net loss of 7 billion RMB for the full year, with a year-on-year revenue plummet of 21.4%.
In an internal memo, then ZTE Chairman Yin Yimin wrote, "We are in a complex industry that heavily relies on the global supply chain." At that time, this statement was both reflective and resigned.
Eight years later, on February 26, 2026, Chinese AI unicorn DeepSeek announced that its upcoming V4 multimodal large model would prioritize deep collaboration with domestic chip manufacturers, achieving for the first time a full-process non-NVIDIA solution from pre-training to fine-tuning.
To put it simply: we no longer need NVIDIA.
Upon hearing this news, the market's initial reaction was skepticism. With NVIDIA holding over 90% of the global AI training chip market share, is it commercially reasonable to abandon it?
However, behind DeepSeek's choice lies a question much larger than business logic: What kind of computing independence does Chinese AI truly need?
What Was Really Choking Us
Many people think that the chip ban was blocking hardware. But what truly suffocated Chinese AI companies was something called CUDA.
CUDA, short for Compute Unified Device Architecture, is a parallel computing platform and programming model introduced by NVIDIA in 2006. It allows developers to directly harness the computing power of NVIDIA GPUs to accelerate various complex computing tasks.
Before the AI era, this was just a tool for a small number of geeks. But when the wave of deep learning arrived, CUDA became the foundation of the entire AI industry.
The training of AI large models is essentially massive matrix operations, which happens to be GPU's strong suit.
Thanks to NVIDIA's early positioning, CUDA has provided a complete toolchain from low-level hardware to upper-level applications for AI developers worldwide. Today, all mainstream AI frameworks globally, from Google's TensorFlow to Meta's PyTorch, are deeply integrated with CUDA at the core.
An AI Ph.D. student, from day one of enrollment, learns, programs, and experiments in the CUDA environment. Every line of code they write reinforces NVIDIA's moat.

By 2025, the CUDA ecosystem has attracted over 4.5 million developers, covering 3000+ GPU-accelerated applications, with over 40,000 companies worldwide using CUDA. This number means that over 90% of AI developers globally are locked into NVIDIA's ecosystem.
The frightening aspect of CUDA is that it is a flywheel. The more developers use it, the more tools, libraries, and code are generated, making the ecosystem more prosperous. The more prosperous the ecosystem, the more developers it attracts. Once this flywheel starts spinning, it is almost impossible to shake.
The result is that NVIDIA sells you the most expensive shovel and defines the only mining posture. Want to switch shovels? You can. But first, you have to rewrite all the experience, tools, and code accumulated by hundreds of thousands of the world's smartest brains over the past decade in this posture.
Who bears this cost?
So when on October 7, 2022, the first round of BIS regulations landed, restricting the export of NVIDIA A100 and H100 to China, Chinese AI companies collectively experienced a ZTE-style suffocation for the first time. NVIDIA subsequently launched the "China Special Edition" A800 and H800, reducing the interchip bandwidth to barely maintain supply.
However, just one year later, on October 17, 2023, the second round of regulations tightened again, and A800 and H800 were also banned, with 13 Chinese companies being added to the entity list. NVIDIA had to introduce the further castrated H20. By December 2024, in the final round of regulations during the Biden administration's term, even the export of H20 was severely restricted.
Tripartite Control, Layered Escalation.
But this time, the storyline is completely different from ZTE's back then.
An Asymmetric Breakout
Under the ban, everyone thought that China's AI dream of large models would come to an end.
They were all wrong. Faced with the blockade, Chinese companies did not choose a head-on confrontation but instead embarked on a breakout. The first battlefield of this breakout was not in chips but in algorithms.
From late 2024 to 2025, Chinese AI companies collectively shifted to a technical direction: Hybrid Expert Models.
In simple terms, it is splitting a huge model into many small experts, activating only the most relevant ones during tasks, rather than having the entire model in motion.
DeepSeek's V3 is a typical representative of this approach. It has 671 billion parameters, but only activates 37 billion of them during each inference, accounting for just 5.5% of the total. In terms of training costs, it used 2048 NVIDIA H800 GPUs, took 58 days to train, and cost a total of 5.576 million dollars. For comparison, the estimated training cost of GPT-4 is around 78 million dollars. A difference of an order of magnitude.
The extreme optimization on algorithms is directly reflected in the pricing. DeepSeek's API price is only $0.028 to $0.28 per million tokens for input and $0.42 per output, while GPT-4's input price is $5, and output is $15. Claude Opus is even more expensive, with input at $15 and output at $75. By conversion, DeepSeek is 25 to 75 times cheaper than Claude.
This price difference had a significant impact on the global developer market. In February 2026, on OpenRouter, the world's largest AI model API aggregation platform, China's AI model weekly call volume surged by 127% within three weeks, surpassing the United States for the first time. A year ago, China's model share on OpenRouter was less than 2%. A year later, it had grown by 421%, approaching sixty percent.
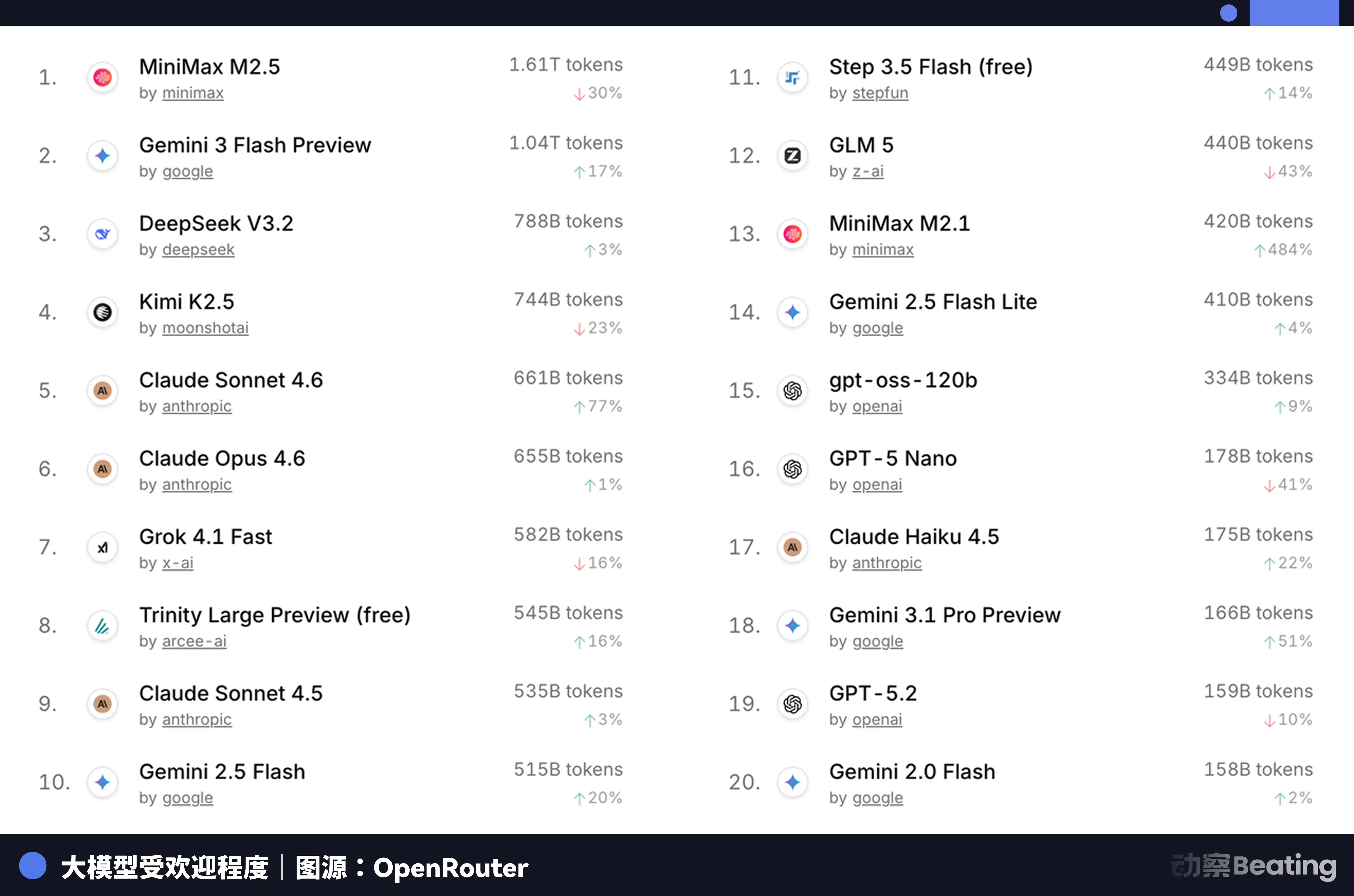
Behind this data is a structurally overlooked change. Starting in the second half of 2025, the mainstream scenario for AI applications shifted from chat to Agent. In an Agent scenario, the token consumption per task is 10 to 100 times that of simple chat. When token consumption grows exponentially, price becomes a decisive factor. The extreme cost-effectiveness of Chinese models happened to hit this window.
However, the problem is that the reduction in inference costs has not solved the fundamental issue of training. If a large model cannot sustain training and iteration on the latest data, its capability quickly degrades. And training remains the unavoidable power-hungry black hole.
So, where does the "shovel" for training come from?
The Promotion of Reserves
Xinghua, Jiangsu, a small city in central Jiangsu known for stainless steel and health food, had no previous connection to AI. However, in 2025, a 148-meter-long domestic computing power server production line was established and put into operation here, taking only 180 days from contract signing to production.
The core of this production line consists of two fully domestic chips: the Loongson 3C6000 processor and the Taichi Element T100 AI acceleration card. The Loongson 3C6000 was independently developed from instruction set to microarchitecture. The Taichi Element was derived from the National Supercomputing Center in Wuxi and a team from Tsinghua University, utilizing heterogeneous multi-core architecture.
When running at full capacity, this production line can roll out one server every 5 minutes. The total investment in this production line is 1.1 billion RMB, with an estimated annual output of 100,000 units.
More importantly, the ten-thousand-card cluster composed of these domestic chips has begun to undertake real large-scale model training tasks.
In January 2026, Zhipu AI and Huawei jointly released GLM-Image, the first SOTA image generation model to be fully trained relying on domestic chips. In February, China Telecom's billion-scale "Xingchen" large model completed end-to-end training on a domestically produced ten-thousand-card computing power pool in Lingang, Shanghai.

The significance of these cases is that they prove one thing: domestic chips have transitioned from "usable for inference" to "usable for training." This is a qualitative change. Inference only requires running pre-trained models, with relatively low chip requirements; whereas training involves handling massive data, performing complex gradient calculations and parameter updates, with demands on chip computation power, interconnect bandwidth, and software ecosystem an order of magnitude higher.
The core force undertaking these tasks is Huawei's Ascend series chips. By the end of 2025, the number of developers in the Ascend ecosystem had exceeded 4 million, with over 3,000 partners. Forty-three mainstream industry large models had completed pre-training based on Ascend, over 200 open-source models had been adapted. At the MWC conference on March 2, 2026, Huawei also launched a new generation of computing power base SuperPoD for overseas markets.
The FP16 computing power of Ascend 910B has already caught up with NVIDIA A100. Although the gap still exists, it has changed from unavailable to available, and from available to becoming usable. Ecosystem development cannot wait until the chip is perfect before starting. It must be massively deployed in the usable stage, using real business needs to drive the iteration of chips and software. Bytedance, Tencent, and Baidu aim to import domestically made computing power servers, with a widespread doubling in 2026 compared to the previous year. Ministry of Industry and Information Technology data shows that China's smart computing scale has reached 1590 EFLOPS. In 2026, it is becoming the first year of domestic computing power scale deployment.
American Power Shortage and China's Overseas Expansion
In early 2026, Virginia, which carries a large amount of global data center traffic, suspended the approval of new data center construction projects. Georgia followed suit, with approval suspensions extended to 2027. Illinois and Michigan have also introduced restrictive measures.
According to the International Energy Agency, in 2024, U.S. data centers consumed 183 terawatt-hours of electricity, accounting for about 4% of the national total electricity consumption. By 2030, this number is expected to double to 426TWh, with the share possibly exceeding 12%. Arm's CEO even predicts that by 2030, AI data centers will consume 20% to 25% of the U.S.'s electricity.
The U.S. power grid is already overwhelmed. The PJM grid covering 13 states in the eastern U.S. is facing a 6GW capacity shortage. By 2033, the U.S. as a whole will face a 175GW power capacity gap, equivalent to the electricity consumption of 130 million households. Wholesale power costs in data center-concentrated areas have increased by 267% compared to five years ago.
At the end of computing power lies energy. And in this energy dimension, the gap between China and the U.S. is even greater than in chips, just in the opposite direction.
China's annual electricity generation is 10.4 trillion kWh, compared to the U.S.'s 4.2 trillion kWh, making China 2.5 times that of the U.S. More importantly, residential electricity consumption accounts for only 15% of China's total electricity usage, while in the U.S., this proportion is 36%. This means that China has a far larger industrial electricity surplus than the U.S. to invest in computing infrastructure.
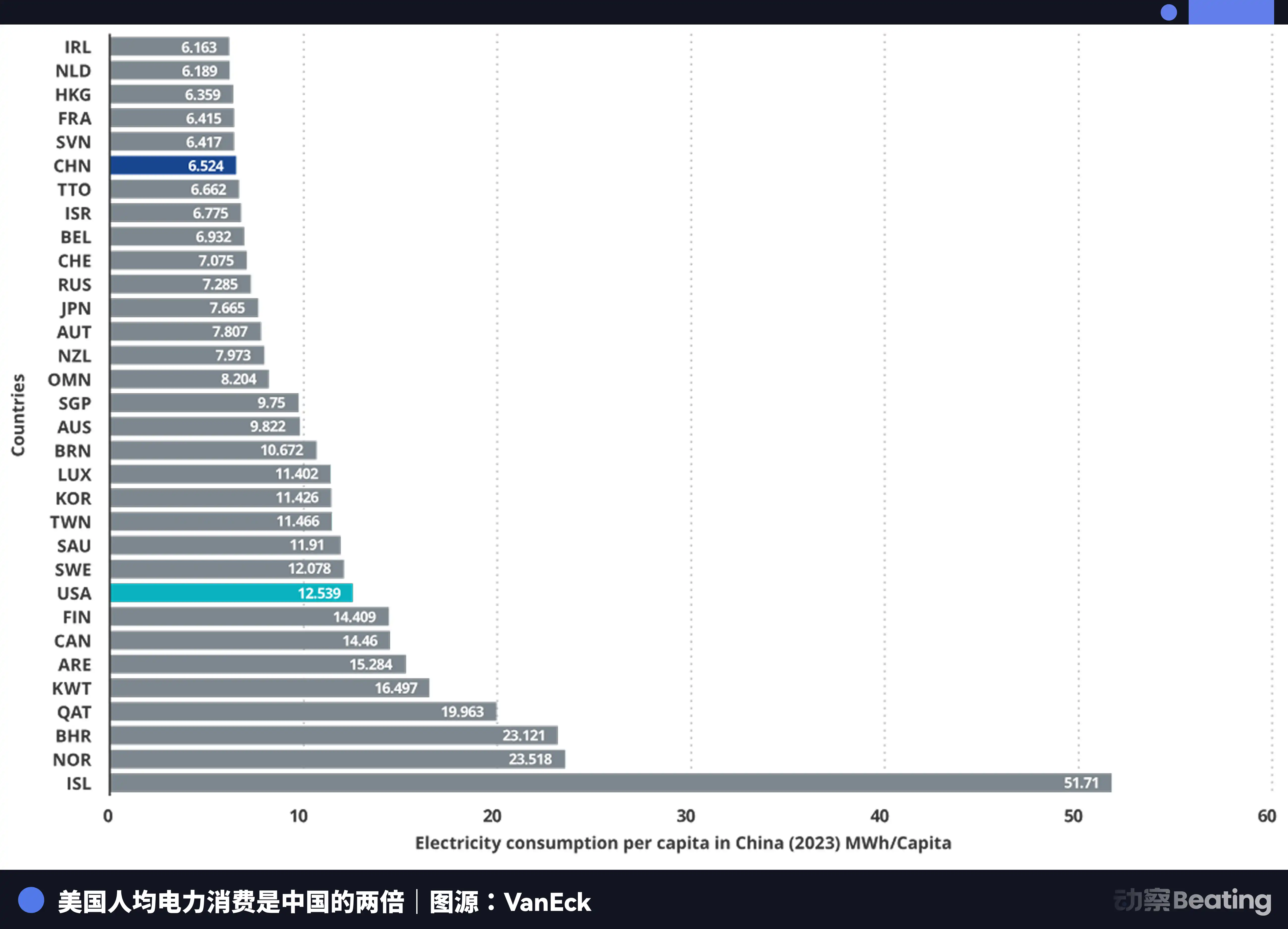
In terms of electricity prices, the electricity price in the AI company cluster area in the U.S. ranges from 0.12 to 0.15 USD per kWh, while the industrial electricity price in western China is about 0.03 USD, only a quarter to a fifth of the U.S. price.
China's electricity generation increment has reached 7 times that of the U.S.
Just as the United States was worrying about its electricity supply, China's AI was quietly going global. But this time, what went global was not a product or a factory, but a Token.
Token, the smallest unit for AI model information processing, is becoming a new digital commodity. It is produced in China's computing power factories and transported globally through undersea cables.
DeepSeek's user distribution data tells a compelling story: China accounts for 30.7%, India 13.6%, Indonesia 6.9%, the United States 4.3%, and France 3.2%. It supports 37 languages and is popular in emerging markets like Brazil. Globally, 26,000 companies have opened accounts, and 3,200 institutions have deployed the enterprise version.
By 2025, 58% of new AI startups have integrated DeepSeek into their tech stack. In China, DeepSeek has captured 89% of the market share. In other sanctioned countries, the market share ranges from 40% to 60%.
This scene is strikingly similar to another war over industrial autonomy forty years ago.
In 1986, under intense pressure from the United States, the Japanese government signed the "U.S.-Japan Semiconductor Agreement." The core provisions of the agreement had three main points: Japan was required to open its semiconductor market, U.S. chip market share in Japan had to reach 20% or more; Japan was forbidden from exporting semiconductors below cost; a 100% punitive tariff was imposed on $300 million worth of chips exported from Japan. At the same time, the U.S. vetoed Fujitsu's acquisition of Fairchild Semiconductor.
That year, the Japanese semiconductor industry was at its peak. By 1988, Japan controlled 51% of the global semiconductor market share, while the U.S. had only 36.8%. Out of the world's top ten semiconductor companies, Japan held six positions: NEC at second, Toshiba at third, Hitachi at fifth, Fujitsu at seventh, Mitsubishi at eighth, Panasonic at ninth. In 1985, Intel suffered a $173 million loss in the U.S.-Japan semiconductor battle, teetering on the brink of bankruptcy.
But everything changed after the agreement was signed.
Using measures such as the 301 investigation, the U.S. launched a comprehensive suppression of Japanese semiconductor companies. At the same time, it supported Samsung and Hynix in Korea to impact the Japanese market with lower prices. Japan's DRAM market share plummeted from 80% to 10%. By 2017, Japan's IC market share was only 7%. The once dominant giants were either split up, acquired, or quietly exited amid endless losses.
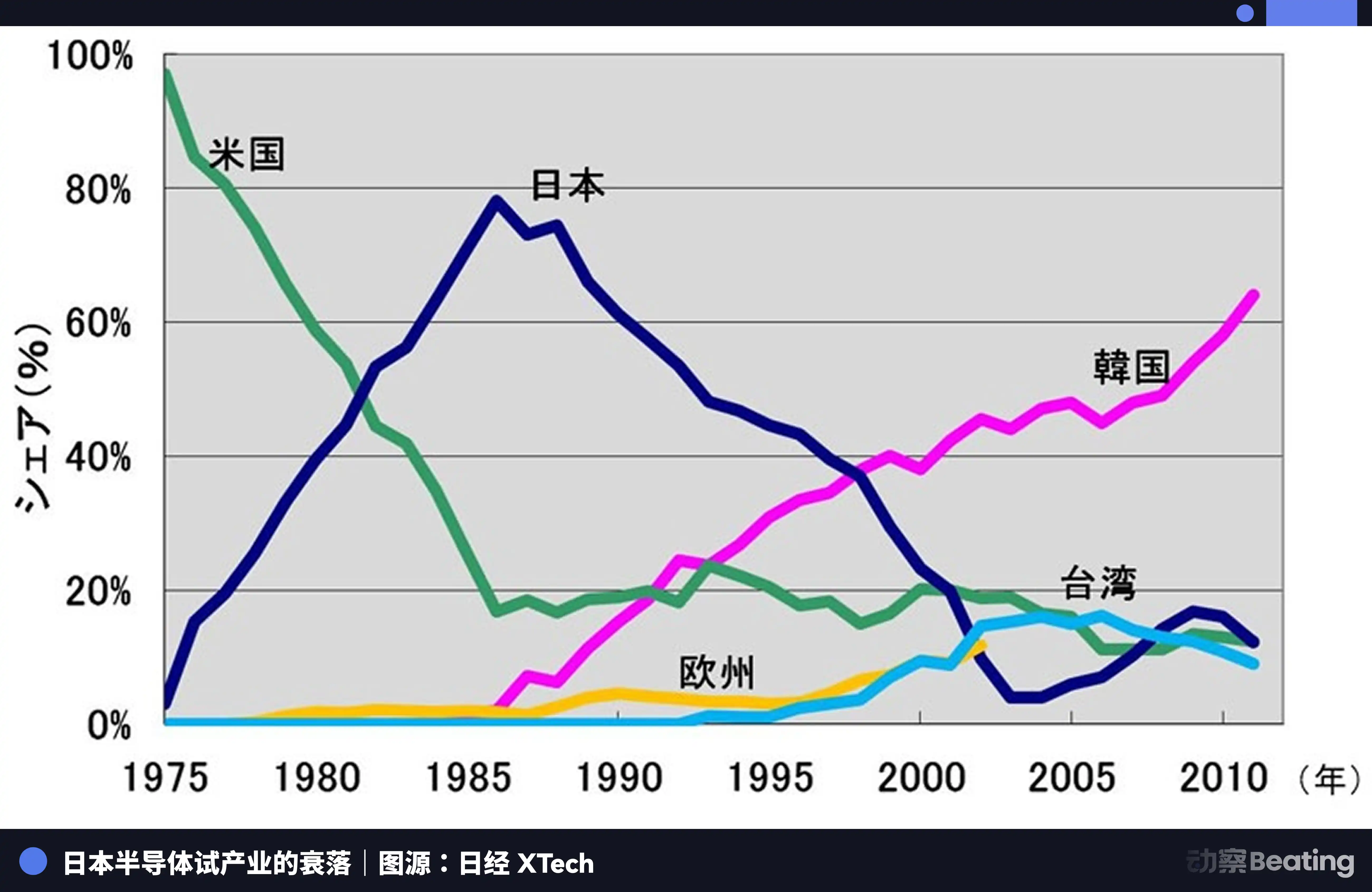
The tragedy of the Japanese semiconductor industry is that it was content to be the best producer in a global division of labor dominated by a single external force, but never thought to build its own independent ecosystem. When the tide ebbed, it found itself with nothing beyond production itself.
Today's Chinese AI industry is standing at a similar yet entirely different crossroads.
Similar in that we also face tremendous pressure from external forces. The three rounds of chip control, escalating layers of barriers, and the towering walls of the CUDA ecosystem.
What is different is that this time, we have chosen a more difficult path. From algorithm-level optimization to the leap of domestic chips from inference to training, to the accumulation of the Ascend ecosystem's 4 million developers, to the penetration of global markets through Token globalization. Each step on this path is building an independent industrial ecosystem that Japan never had.
Epilogue
On February 27, 2026, performance reports from three local AI chip companies were released on the same day.
Cambricon, revenue surged by 453%, achieving annual profit for the first time. Moore Threads, revenue grew by 243%, but with a net loss of 1 billion. Horizon, revenue increased by 121%, with a net loss of nearly 800 million.
Half flame, half seawater.
The flame is the market's extreme thirst. The 95% gap relinquished by Jensen Huang is being gradually filled inch by inch by the revenue figures of these local companies. Regardless of performance or ecosystem, the market needs a second option beyond NVIDIA. This is a rare structural opportunity torn open by geopolitics.
The seawater is the high cost of ecosystem development. Every penny of loss is real money paid to catch up with the CUDA ecosystem. It is investment in research and development, software subsidies, and the manpower cost of engineers deployed to customer sites solving compilation issues one by one. These losses are not due to mismanagement but are the war tax required to build an independent ecosystem.
These three financial reports paint a more honest picture of the reality of this computational power war than any industry report. It is not a triumphant advance but a fierce battlefield engagement fought with bloodshed.
But the form of war has indeed changed. Eight years ago, we discussed the question of "whether we can survive." Today, we discuss the question of "how high a price we must pay to survive."
The price itself is progress.
You may also like

22x Subsidy to 1 USD Revenue: How Long Can the TAO Growth Myth Last?

Use the Claude Wisely, One Piece is Enough

Netflix is Set to Bring FTX's Story to the Screen: Portraying History or Glamorizing a Scam?

People unable to buy Anthropic have driven its shadow stock up 16x

LALIGA Match Report: Vinícius scores as 10-man Real Madrid secure a 3-2 comeback victory in Madrid derby
In the early hours of March 23, 2026, Round 29 of LALIGA delivered a headline clash at the Santiago Bernabéu. Real Madrid hosted their local rivals, Atlético de Madrid, in a high-stakes encounter. Under referee José Munuera, the match unfolded at a fierce pace, packed with physical duels and momentum swings. After a five-goal thriller, Real Madrid held firm for a 3–2 home win, taking all three points. They remain second on 69 points, now four behind leaders Barcelona.
From a numbers standpoint, Real Madrid stayed composed under pressure, completing 526 passes with a 52.4% share of possession. Atlético struck first in the 33rd minute through Lookman. After the break, Real Madrid flipped the game: Vinícius converted a penalty to level, then Valverde fired them ahead. Molina pulled Atlético back on level terms, but Vinícius stepped up again in the 72nd minute to seal the win. Late drama followed as Valverde saw red, forcing Real Madrid to defend deep with ten men through the final stretch. Atlético's aggressive approach—12 fouls and 4 yellow cards—kept the pressure on, but they couldn’t stop the comeback.
WEEX Insights: As the official LALIGA partner in the Hong Kong and Taiwan regions, WEEX sees this win as a masterclass in control under pressure. Even after a red card and constant attacks, Real Madrid stayed sharp and executed with precision. That same discipline—staying calm in volatile moments and acting with clarity—reflects the core trading mindset WEEX stands for. LALIGA fan campaigns are coming soon—celebrate the game with WEEX.
About WEEX
Founded in 2018, WEEX has developed into a global crypto exchange with over 6.2 million users across more than 150 countries. The platform emphasizes security, liquidity, and usability, providing over 1,200 spot trading pairs and offering up to 400x leverage in crypto futures trading. In addition to the traditional spot and derivatives markets, WEEX is expanding rapidly in the AI era — delivering real-time AI news, empowering users with AI trading tools, and exploring innovative trade-to-earn models that make intelligent trading more accessible to everyone. Its 1,000 BTC Protection Fund further strengthens asset safety and transparency, while features such as copy trading and advanced trading tools allow users to follow professional traders and experience a more efficient, intelligent trading journey.
Follow WEEX on social media
X: @WEEX_Official
Instagram: @WEEX Exchange
Tiktok: @weex_global
Youtube: @WEEX_Official
Discord: WEEX Community
Telegram: WeexGlobalGroup

LALIGA Match Report: Araujo seals 1–0 win as Barça tighten grip on top spot
In the early hours of March 22 (Beijing Time), Barça edged Rayo Vallecano 1–0 at Camp Nou in a key Round 29 clash. The hard-earned win lifts Barça to 73 points, strengthening their hold on first place.
Barça controlled the game with 61% possession and a sharp 89% passing accuracy (460 passes). Rayo pushed back with intensity, earning 9 corners, but Barça's defense stayed solid. Yellow cards for Raphinha, Yamal, and Cubarsí highlighted the physical edge of the match. Second-half subs like Rashford and Olmo added fresh energy to help see out the result. Rayo remain 14th on 32 points.
WEEX Insights: As the Official LALIGA Partner in HK & TW, WEEX sees Barça’s 89% passing accuracy as a clear example of high execution with minimal error. Staying precise under pressure and finding the breakthrough reflects the same disciplined approach used in rational trading.
LALIGA interactive campaigns are coming soon—stay tuned with WEEX ⚽️
About WEEX
Founded in 2018, WEEX has developed into a global crypto exchange with over 6.2 million users across more than 150 countries. The platform emphasizes security, liquidity, and usability, providing over 1,200 spot trading pairs and offering up to 400x leverage in crypto futures trading. In addition to the traditional spot and derivatives markets, WEEX is expanding rapidly in the AI era — delivering real-time AI news, empowering users with AI trading tools, and exploring innovative trade-to-earn models that make intelligent trading more accessible to everyone. Its 1,000 BTC Protection Fund further strengthens asset safety and transparency, while features such as copy trading and advanced trading tools allow users to follow professional traders and experience a more efficient, intelligent trading journey.
Follow WEEX on social media
X: @WEEX_Official
Instagram: @WEEX Exchange
Tiktok: @weex_global
Youtube: @WEEX_Official
Discord: WEEX Community
Telegram: WeexGlobalGroup
These days, even hackers are losing money
Arm Chips In-House: Rewire News Brief

IOSG: Stablecoin Reshaping Asia Cross-Border Payments? Strategic Landscape and Investment Opportunities Analysis

\$73 Billion OpenAI Aims for IPO: Drops Sora, Snubs Disney, Puts Microsoft in Risk Factors

The Chip Industry's Most Secure Middleman Just Took a Very Risky Turn

CZ's Latest Interview: My Experience is Replicable, Writing a Book to Inspire Young Entrepreneurs

Morning News | Invesco acquires a $900 million on-chain fund from Superstate; ParaFi has raised $125 million for its new fund; Solana Foundation launches developer platform SDP

What is the background of this new fund that the two major prediction market platforms have rarely joined forces to create?

SIREN, another leveraged scam

Token has become extremely popular, and the blockchain is very sad

Tether's major shareholder invests £12 million to support the "British version of Trump" in the cryptocurrency sector

Huang Renxun's Latest Podcast: Will NVIDIA Reach $1 Trillion? Will the Number of Programmers Increase Instead of Decrease? How to Deal with AI Anxiety?
22x Subsidy to 1 USD Revenue: How Long Can the TAO Growth Myth Last?
Use the Claude Wisely, One Piece is Enough
Netflix is Set to Bring FTX's Story to the Screen: Portraying History or Glamorizing a Scam?
People unable to buy Anthropic have driven its shadow stock up 16x
LALIGA Match Report: Vinícius scores as 10-man Real Madrid secure a 3-2 comeback victory in Madrid derby
In the early hours of March 23, 2026, Round 29 of LALIGA delivered a headline clash at the Santiago Bernabéu. Real Madrid hosted their local rivals, Atlético de Madrid, in a high-stakes encounter. Under referee José Munuera, the match unfolded at a fierce pace, packed with physical duels and momentum swings. After a five-goal thriller, Real Madrid held firm for a 3–2 home win, taking all three points. They remain second on 69 points, now four behind leaders Barcelona.
From a numbers standpoint, Real Madrid stayed composed under pressure, completing 526 passes with a 52.4% share of possession. Atlético struck first in the 33rd minute through Lookman. After the break, Real Madrid flipped the game: Vinícius converted a penalty to level, then Valverde fired them ahead. Molina pulled Atlético back on level terms, but Vinícius stepped up again in the 72nd minute to seal the win. Late drama followed as Valverde saw red, forcing Real Madrid to defend deep with ten men through the final stretch. Atlético's aggressive approach—12 fouls and 4 yellow cards—kept the pressure on, but they couldn’t stop the comeback.
WEEX Insights: As the official LALIGA partner in the Hong Kong and Taiwan regions, WEEX sees this win as a masterclass in control under pressure. Even after a red card and constant attacks, Real Madrid stayed sharp and executed with precision. That same discipline—staying calm in volatile moments and acting with clarity—reflects the core trading mindset WEEX stands for. LALIGA fan campaigns are coming soon—celebrate the game with WEEX.
About WEEX
Founded in 2018, WEEX has developed into a global crypto exchange with over 6.2 million users across more than 150 countries. The platform emphasizes security, liquidity, and usability, providing over 1,200 spot trading pairs and offering up to 400x leverage in crypto futures trading. In addition to the traditional spot and derivatives markets, WEEX is expanding rapidly in the AI era — delivering real-time AI news, empowering users with AI trading tools, and exploring innovative trade-to-earn models that make intelligent trading more accessible to everyone. Its 1,000 BTC Protection Fund further strengthens asset safety and transparency, while features such as copy trading and advanced trading tools allow users to follow professional traders and experience a more efficient, intelligent trading journey.
Follow WEEX on social media
X: @WEEX_Official
Instagram: @WEEX Exchange
Tiktok: @weex_global
Youtube: @WEEX_Official
Discord: WEEX Community
Telegram: WeexGlobalGroup
LALIGA Match Report: Araujo seals 1–0 win as Barça tighten grip on top spot
In the early hours of March 22 (Beijing Time), Barça edged Rayo Vallecano 1–0 at Camp Nou in a key Round 29 clash. The hard-earned win lifts Barça to 73 points, strengthening their hold on first place.
Barça controlled the game with 61% possession and a sharp 89% passing accuracy (460 passes). Rayo pushed back with intensity, earning 9 corners, but Barça's defense stayed solid. Yellow cards for Raphinha, Yamal, and Cubarsí highlighted the physical edge of the match. Second-half subs like Rashford and Olmo added fresh energy to help see out the result. Rayo remain 14th on 32 points.
WEEX Insights: As the Official LALIGA Partner in HK & TW, WEEX sees Barça’s 89% passing accuracy as a clear example of high execution with minimal error. Staying precise under pressure and finding the breakthrough reflects the same disciplined approach used in rational trading.
LALIGA interactive campaigns are coming soon—stay tuned with WEEX ⚽️
About WEEX
Founded in 2018, WEEX has developed into a global crypto exchange with over 6.2 million users across more than 150 countries. The platform emphasizes security, liquidity, and usability, providing over 1,200 spot trading pairs and offering up to 400x leverage in crypto futures trading. In addition to the traditional spot and derivatives markets, WEEX is expanding rapidly in the AI era — delivering real-time AI news, empowering users with AI trading tools, and exploring innovative trade-to-earn models that make intelligent trading more accessible to everyone. Its 1,000 BTC Protection Fund further strengthens asset safety and transparency, while features such as copy trading and advanced trading tools allow users to follow professional traders and experience a more efficient, intelligent trading journey.
Follow WEEX on social media
X: @WEEX_Official
Instagram: @WEEX Exchange
Tiktok: @weex_global
Youtube: @WEEX_Official
Discord: WEEX Community
Telegram: WeexGlobalGroup